评估实时性能#
介绍#
Autoware 在集成到服务时应该是实时系统.因此,每次回调的响应时间应尽可能短.如果 Autoware 似乎很慢,则必须进行性能测量并根据分析实施改进.然而,Autoware 是一个复杂的软件系统,包含许多 ROS 2 节点,这可能会使识别瓶颈的过程复杂化.为了应对这一挑战,我们将讨论对 Autoware 进行详细性能测量的方法,并提供案例研究.值得注意的是,多种因素都可能导致性能不佳,例如 OS 层的调度和内存分配,但我们本页的重点将放在用户代码瓶颈上.本节的大纲如下:
- 性能测量
- 单节点执行
- 准备分离的芯
- 单独运行单个节点
- 测量和可视化
- 案例研究
- 传感组件
- 规划组件
性能衡量#
没有精确的测量,就不可能有改进. 要测量应用程序代码的性能,必须消除任何外部影响. 这些影响包括来自作系统和 CPU 频率波动的干扰. 当核心资源被多个线程共享时,也会产生调度效果. 本节概述了一种准确测量特定节点的应用程序代码性能的技术. 虽然本节只讨论 Intel CPU 上的 Linux 的情况,但在其他环境中也应考虑类似的因素.
单节点执行#
为了消除调度的影响,被测节点应独立运行,使用与整个 Autoware 系统运行时相同的逻辑.
为此,请记录整个 Autoware 系统运行时要测量的节点的所有 input 主题.
为了实现这一目标,已经准备了一个名为 ros2_single_node_replayer 的工具.
有关如何使用该工具的详细信息,请参阅 README. 此工具记录整个 Autoware作期间特定节点的输入主题,并在具有相同逻辑的单个节点中重放该主题. 该工具依赖于 ros2 bag record` 命令,并且从 ROS 2 Humble 开始不支持 service/action 的记录,因此使用 service/action 作为主要逻辑的节点可能无法正常工作.
准备分离的型芯#
运行待测节点的隔离核心必须满足以下条件.
- 修复 CPU 频率并禁用 turbo boost
- 最大限度地减少计时器中断
- 卸载 RCU (Read Copy Update) 回调
- 如果启用了超线程,则隔离配对的内核
要在 Linux 上满足这些条件,需要具有以下内核配置的自定义内核构建. 您可以找到许多资源来指导您如何构建自定义 Linux 内核(例如 这个). 请注意,即使启用了完全无滴答,如果一个内核中存在两个以上的任务,也会生成计时器中断以进行调度.
# 启用 CONFIG_NO_HZ_FULL
-> General setup
-> Timers subsystem
-> Timer tick handling (Full dynticks system (tickless))
(X) Full dynticks system (tickless)
# 允许从选定的 CPU 中卸载 RCU 回调处理
# (CONFIG_RCU_NOCB_CPU=y)
-> General setup
-> RCU Subsystem
-*- Offload RCU callback processing from boot-selected CPUs
此外,需要按如下方式设置内核启动参数.
GRUB_CMDLINE_LINUX_DEFAULT=
"... isolcpus=2,8 rcu_nocbs=2,8 rcu_nocb_poll nohz_full=2,8 intel_pstate=disable`
例如,在上面的配置中,假设要测量的节点运行在核心 2 上,并且核心 8(一个超线程对)也被隔离.
需要根据测量机的缓存和内核布局来适当决定运行哪些内核来运行测量目标以及要隔离哪些节点.
您可以通过运行 cat /proc/softirqs轻松检查它是否配置正确.
由于在内核引导参数中指定了intel_pstate=disable,因此可以在扩展调节器中指定userspace`.
cat /sys/devices/system/cpu/cpu2/cpufreq/scaling_governor // ondemand
sudo sh -c "echo userspace > /sys/devices/system/cpu/cpu2/cpufreq/scaling_governor"
这允许您在定义的范围内自由设置所需的频率.
sudo sh -c "echo <freq(kz)> > /sys/devices/system/cpu/cpu2/cpufreq/scaling_setspeed"
Turbo Boost 需要在 Intel CPU 上关闭,这经常被忽视.
sudo sh -c "echo 0 > /sys/devices/system/cpu/cpufreq/boost"
单独运行单个节点#
按照 ros2_single_node_replayer README 中的说明,启动节点并播放该工具创建的专用 rosbag.
在播放 rosbag 之前,适当设置节点运行线程的 CPU 亲和性,使其放置在准备好的隔离核心上.
taskset --cpu-list -p <target cpu> <pid>
为避免干扰最后一级高速缓存,请尽量减少测量期间运行的其他应用程序的数量.
测量和可视化#
要可视化测量目标的性能,请在目标源代码中嵌入用于记录时间戳和性能计数器值的代码.
为了实现这个目标,我们准备了一个名为 pmu_analyzer 的工具.
有关如何使用该工具的详细信息,请参阅 README. 此工具可以测量源代码中任何部分的周转时间,以及各种性能计数器.
案例研究#
在本节中,我们将介绍几个案例研究,以演示性能改进.这些示例不仅展示了我们对提高系统效率的承诺,而且为可能在自己的项目中面临类似挑战的开发人员提供了宝贵的资源.这里讨论的性能改进涵盖了 Autoware 系统的各个组件,包括传感模块和规划模块.每个组件都有关于哪些点成为瓶颈的趋势.通过检查这些案例研究中采用的方法、技术和工具,读者可以更好地了解优化复杂软件系统(如 Autoware)的实际方面.
传感组件#
首先,我们将以节点 ring_outlier_filter 为例,解释性能提升的过程.
有关详细信息,请参阅 Pull Request.
下图是 ring_outlier_filter 主要处理部分的周转时间的时间序列图,如上面的 性能测量 部分所述进行分析.
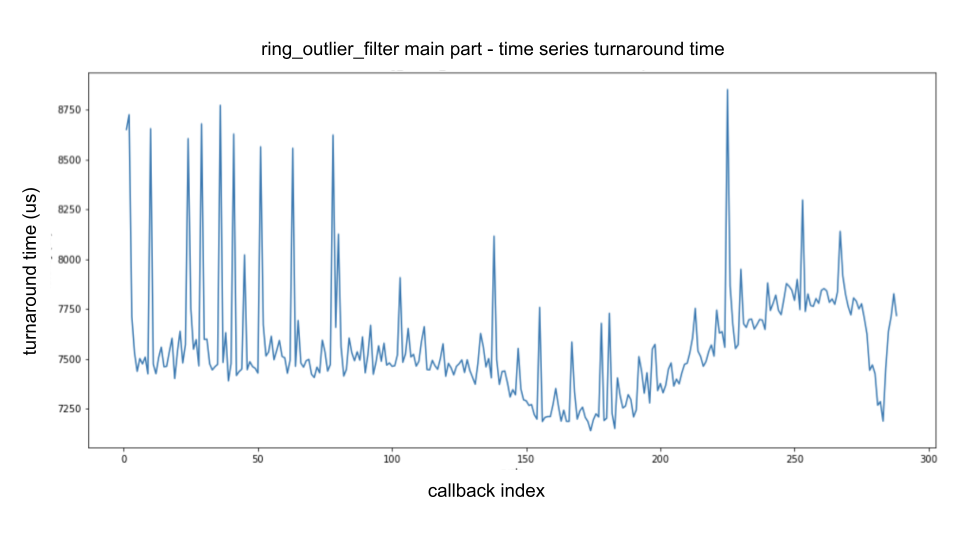
横轴表示调用的回调数量(即回调索引),纵轴表示周转时间.
从性能计数器的角度分析传感模块的性能时,请注意 指令 、 LLC 负载未命中 、 LLC 存储未命中 、 缓存未命中 和 轻微故障 .
对性能计数器的分析表明,最大的波动来自 次要错误 (即软页面错误),第二动来自 LLC-store-misses 和 LLC-load-misses (即最后一级缓存中的缓存未命中),最慢的波动来自指令(即消息数据大小波动).
例如,当我们在横轴上绘制 次要故障 ,在纵轴上绘制周转时间时,我们可以看到以下主导比例关系.
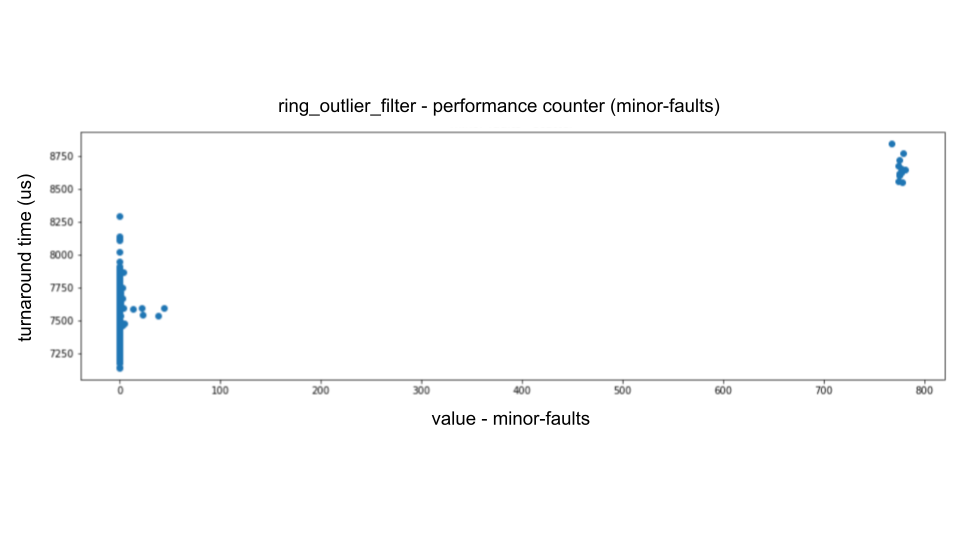
为了实现零软页错误,堆分配只能从预先首先接触的区域进行.
我们开发了一个名为 heaphook 的库,以避免在运行 Autoware 回调时出现软页面错误.
如果您有兴趣,请参考 GitHub 讨论 和 issue.
为了减少 LLC 未命中,有必要减少工作集并使用高速缓存高效的访问模式.
在处理 LiDAR 点云数据等大型消息数据的传感组件中,最大限度地减少复制非常重要.
将传感器数据消息类型作为输入和输出的回调应尽可能以就地算法编写.
这意味着,在下面的伪代码中,当从 input_msg 生成 output_msg 时,尽可能避免使用缓冲区以减少内存副本的数量至关重要.
void callback(const PointCloudMsg &input_msg) {
auto output_msg = allocate_msg<PointCloudMsg>(output_size);
fill(input_msg, output_msg);
publish(std::move(output_msg));
}
为了提高缓存效率,请尽可能实现就地样式,而不是偶尔接触内存区域. 在使用 PCL 的 ROS 应用程序中,经常可以看到如下所示的代码.
void callback(const sensor_msgs::PointCloud2ConstPtr &input_msg) {
pcl::PointCloud<PointT>::Ptr input_pcl(new pcl::PointCloud<PointT>);
pcl::fromROSMsg(*input_msg, *input_pcl);
// Algorithm is described for point cloud type of pcl
pcl::PointCloud<PointT>::Ptr output_pcl(new pcl::PointCloud<PointT>);
fill_pcl(*input_pcl, *output_pcl);
auto output_msg = allocate_msg<sensor_msgs::PointCloud2>(output_size);
pcl::toROSMsg(*output_pcl, *output_msg);
publish(std::move(output_msg));
}
要使用 PCL 库,在回调的开头和结尾使用 fromROSMsg() 和 toROSMsg() 进行消息类型转换.
这是一个浪费的复制过程,应避免.
我们应该通过删除对 PCL 的依赖(例如 https://github.com/tier4/velodyne_vls/pull/39)来消除不必要的类型转换.
对于大型消息类型(如 map 数据),就物理内存而言,整个系统中应该只有一个实例.
规划组件#
首先,我们将在 behavior_velocity_planner 节点中选择 detection_area 模块,该节点的周转时间往往很长.
我们按照上面的性能分析步骤获得了下图.
轴与传感案例研究中的图形相同.
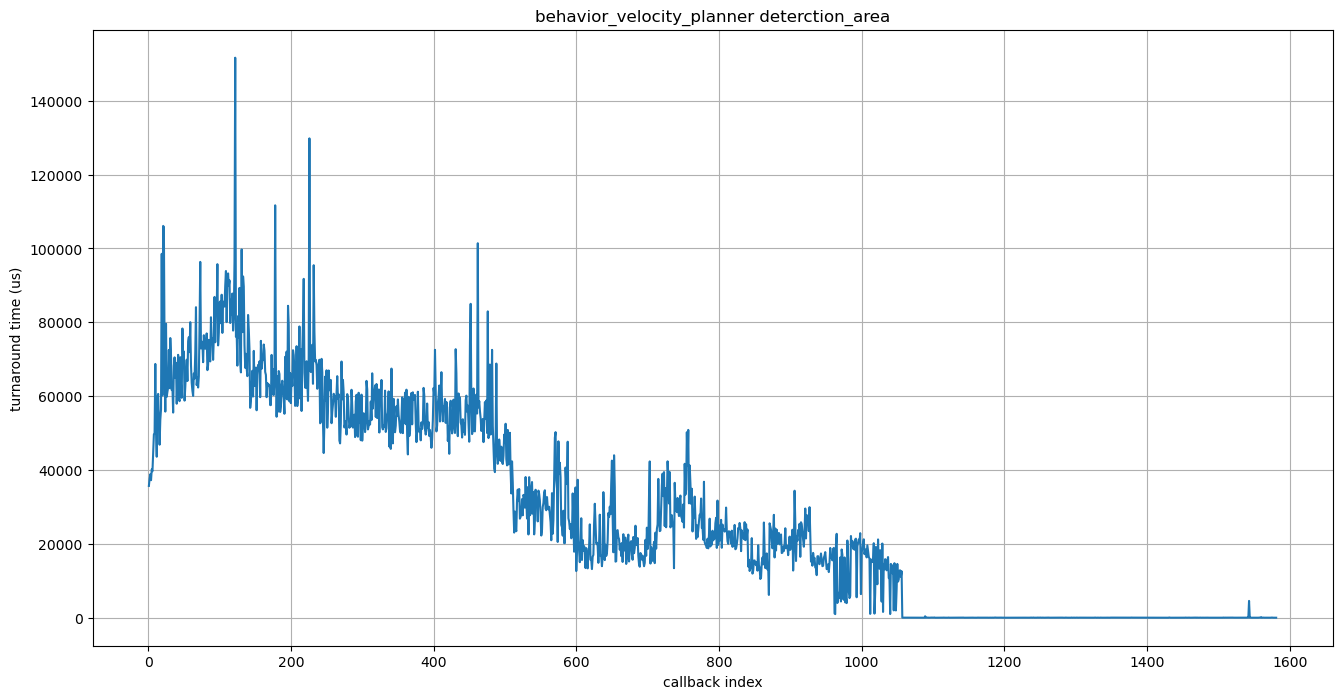
使用 pmu_analyzer 工具进一步识别瓶颈,我们发现以下多个循环占用了大量处理时间:
for ( area : detection_areas )
for ( point : point_clouds )
if ( boost::geometry::within(point, area) )
// do something with O(1)
它检查每个点云是否包含在每个检测区域中.
设 N 是 point_clouds 的大小,M 是 detection_areas 的大小,那么这个程序的计算复杂度是 O(N^2 * M),因为 within 的复杂度是 O(N).在这里,鉴于大多数点云都位于远离某个检测区域的地方,因此可以实现一定的优化.首先,计算完全覆盖检测区域的最小封闭圆,然后检查该圆中是否包含点.大多数点云都可以通过这种方法快速排除,在大多数情况下,我们不必调用 within 函数.下面是优化后的伪代码.
for ( area : detection_areas )
circle = calc_minimum_enclosing_circle(area)
for ( point : point_clouds )
if ( point is in circle )
if ( boost::geometry::within(point, area) )
// do something with O(1)
通过使用 O(N) 算法进行最小封闭圆,该程序的计算复杂度降低到几乎 O(N * (N + M))(请注意,确切的计算复杂度并没有真正改变). 如果您有兴趣,请参考 Pull Request.
与此示例类似,在 planning 组件中,我们考虑了数千到数万个点云、路径中的数千个点(代表我们自己的路线)以及代表周围障碍物和检测区域的多边形,并基于它们重复创建路径.因此,我们使用 for 循环多次访问点云和路径的内容.在大多数情况下,瓶颈在于这些幼稚的 for 循环.在这里,理解 Big O 表示法并降低计算复杂度的顺序会直接导致性能改进.